Published On Feb 27, 2023
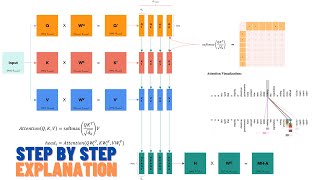
Let's deep dive into the transformer encoder architecture.
ABOUT ME
⭕ Subscribe: https://www.youtube.com/c/CodeEmporiu...
📚 Medium Blog: / dataemporium
💻 Github: https://github.com/ajhalthor
👔 LinkedIn: / ajay-halthor-477974bb
RESOURCES
[ 1🔎] My playlist for all transformer videos before this: • Self Attention in Transformer Neural ...
[ 2 🔎] Transformer Main Paper: https://arxiv.org/abs/1706.03762
PLAYLISTS FROM MY CHANNEL
⭕ ChatGPT Playlist of all other videos: • ChatGPT
⭕ Transformer Neural Networks: • Natural Language Processing 101
⭕ Convolutional Neural Networks: • Convolution Neural Networks
⭕ The Math You Should Know : • The Math You Should Know
⭕ Probability Theory for Machine Learning: • Probability Theory for Machine Learning
⭕ Coding Machine Learning: • Code Machine Learning
MATH COURSES (7 day free trial)
📕 Mathematics for Machine Learning: https://imp.i384100.net/MathML
📕 Calculus: https://imp.i384100.net/Calculus
📕 Statistics for Data Science: https://imp.i384100.net/AdvancedStati...
📕 Bayesian Statistics: https://imp.i384100.net/BayesianStati...
📕 Linear Algebra: https://imp.i384100.net/LinearAlgebra
📕 Probability: https://imp.i384100.net/Probability
OTHER RELATED COURSES (7 day free trial)
📕 ⭐ Deep Learning Specialization: https://imp.i384100.net/Deep-Learning
📕 Python for Everybody: https://imp.i384100.net/python
📕 MLOps Course: https://imp.i384100.net/MLOps
📕 Natural Language Processing (NLP): https://imp.i384100.net/NLP
📕 Machine Learning in Production: https://imp.i384100.net/MLProduction
📕 Data Science Specialization: https://imp.i384100.net/DataScience
📕 Tensorflow: https://imp.i384100.net/Tensorflow
TIMESTAMPS
0:00 Introduction
0:28 Encoder Overview
1:25 Blowing up the encoder
1:45 Create Initial Embeddings
3:54 Positional Encodings
4:54 The Encoder Layer Begins
5:02 Query, Key, Value Vectors
7:37 Constructing Self Attention Matrix
9:44 Why scaling and Softmax?
10:53 Combining Attention heads
12:46 Residual Connections (Skip Connections)
13:45 Layer Normalization
16:36 Why Linear Layers, ReLU, Dropout
17:46 Complete the Encoder Layer
18:46 Final Word Embeddings
20:04 Sneak Peak of Code