Published On Nov 14, 2022
CORRECTION:
00:34:47: that should be "each a dimension of 12x4"
Course playlist: • Natural Language Processing Demystified
Transformers have revolutionized deep learning. In this module, we'll learn how they work in detail and build one from scratch. We'll then explore how to leverage state-of-the-art models for our projects through pre-training and transfer learning. We'll learn how to fine-tune models from Hugging Face and explore the capabilities of GPT from OpenAI. Along the way, we'll tackle a new task for this course: question answering.
Colab notebook: https://colab.research.google.com/git...
Timestamps
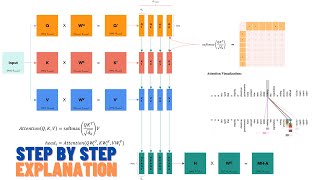
00:00:00 Transformers from scratch
00:01:05 Subword tokenization
00:04:27 Subword tokenization with byte-pair encoding (BPE)
00:06:53 The shortcomings of recurrent-based attention
00:07:55 How Self-Attention works
00:14:49 How Multi-Head Self-Attention works
00:17:52 The advantages of multi-head self-attention
00:18:20 Adding positional information
00:20:30 Adding a non-linear layer
00:22:02 Stacking encoder blocks
00:22:30 Dealing with side effects using layer normalization and skip connections
00:26:46 Input to the decoder block
00:27:11 Masked Multi-Head Self-Attention
00:29:38 The rest of the decoder block
00:30:39 [DEMO] Coding a Transformer from scratch
00:56:29 Transformer drawbacks
00:57:14 Pre-Training and Transfer Learning
00:59:36 The Transformer families
01:01:05 How BERT works
01:09:38 GPT: Language modelling at scale
01:15:13 [DEMO] Pre-training and transfer learning with Hugging Face and OpenAI
01:51:48 The Transformer is a "general-purpose differentiable computer"
This video is part of Natural Language Processing Demystified --a free, accessible course on NLP.
Visit https://www.nlpdemystified.org/ to learn more.